I have heard multiple times from different sources that building from git source instead of using tarballs invalidates this exploit, but I do not understand how. Is anyone able to explain that?
If malicious code is in the source, and therefore in the tarball, what’s the difference?
The tarballs are the official distributions of the source code. The maintainer had git remove the malicious entry point when pushing the newest versions of the source code while retaining it inside these distributions.
All of this would be avoided if Debian downloaded from GitHub’s distributions of the source code, albeit unsigned.
All of this would be avoided if Debian downloaded from GitHub’s distributions of the source code, albeit unsigned.
In that case they would have just put it in the repo, and I’m not convinced anyone would have caught it. They may have obfuscated it slightly more.
It’s totally reasonable to trust a tarball signed by the maintainer, but there probably needs to be more scrutiny when a package changes hands like this one did.
Another reason it didn’t get hit is that the exploit is debian/redhat-specific, checking for files and env variables that just aren’t present when nix builds it. That doesn’t mean that nix couldn’t be targeted, though. Also it’s a bit iffy that replacing the package on unstable took in the order of 10 days which is 99.99% build time because it’s a full rebuild. Much better on stable but it’s not like unstable doesn’t get regular use by people, especially as you can mix+match when running NixOS.
It’s probably a good idea to make a habit of pulling directly from github (generally, VCS). Nix checks hashes all the time so upstream doing a sneak change would break the build, it’s more about the version you’re using being the one that has its version history published. Also: Why not?
Overall, who knows what else is hidden in that code, though. I’ve heard that Debian wants to roll back a whole two years and that’s probably a good idea and in general we should be much more careful about the TCB. Actually have a proper TCB in the first place, which means making it small and simple. Compilers are always going to be an issue as small is not an option there but the likes of http clients, decompressors and the like? Why can they make coffee?
I don’t understand the actual mechanics of it, but my understanding is that it’s essentially like what happened with Volkswagon and their diesel emissions testing scheme where it had a way to know it was being emissions tested and so it adapted to that.
The malicious actor had a mechanism that exempted the malicious code when built from source, presumably because it would be more likely to be noticed when building/examining the source.
Edit: a bit of grammar. Also, this is my best understanding based on what I’ve read and videos I’ve watched, but a lot of it is over my head.
it had a way to know it was being emissions tested and so it adapted to that.
Not sure why you got downvoted. This is a good analogy. It does a lot of checks to try to disable itself in testing environments. For example, setting TERM will turn it off.
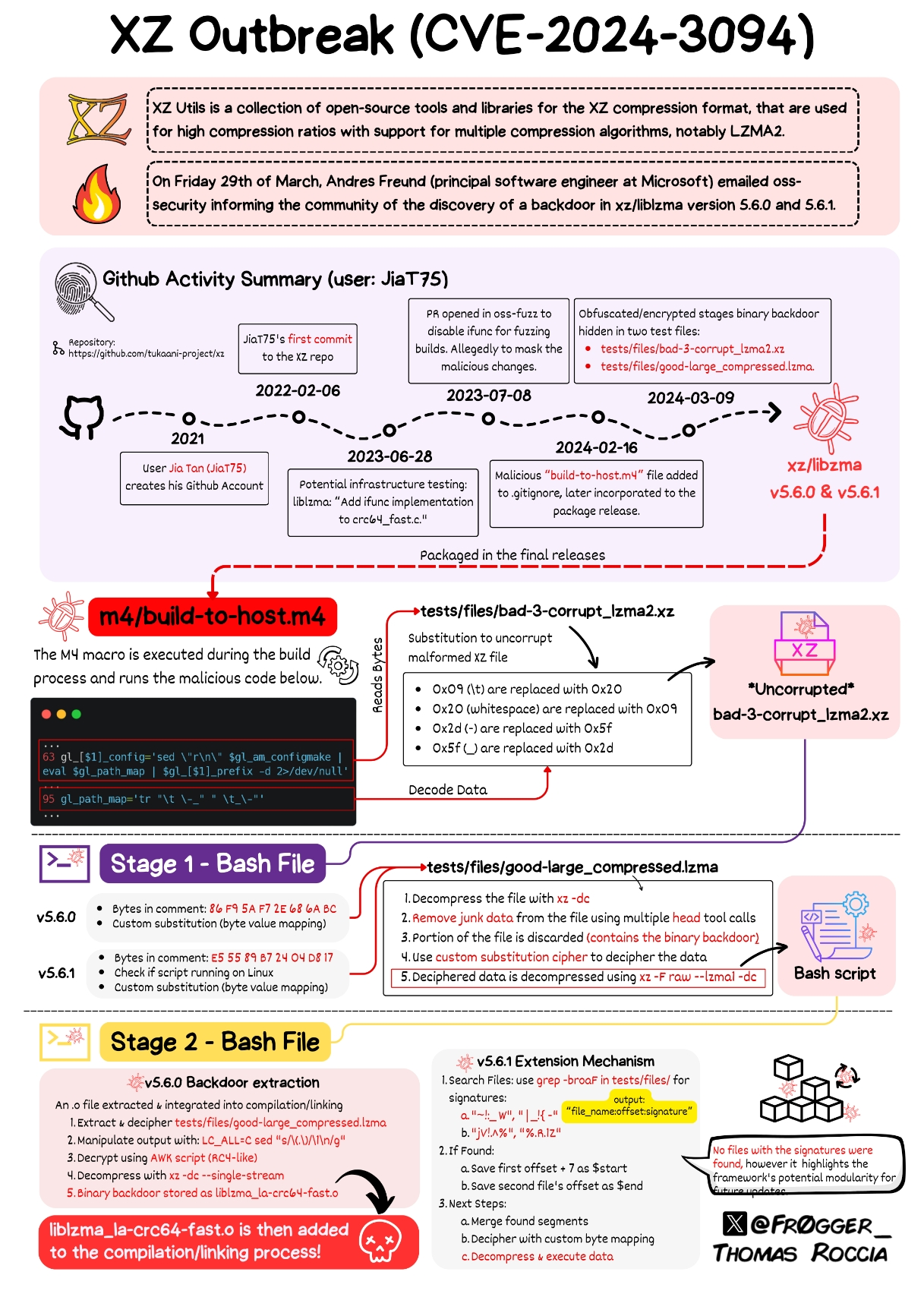
The malicious code is not on the source itself, it’s on tests and other files.
The building process hijacks the code and inserts the malicious content, while the code itself is clean,
So the co-manteiner was able to keep it hidden in plain sight.
The malicious code wasn’t in the source code people typically read (the GitHub repo) but was in the code people typically build for official releases (the tarball). It was also hidden in files that are supposed to be used for testing, which get run as part of the official building process.
The malicious code was written and debugged at their convenience and saved as an object module linker file that had been stripped of debugger symbols (this is one of its features that made Fruend suspicious enough to keep digging when he profiled his backdoored ssh looking for that 500ms delay: there were no symbols to attribute the cpu cycles to).
It was then further obfuscated by being chopped up and placed into a pure binary file that was ostensibly included in the tarballs for the xz library build process to use as a test case file during its build process. The file was supposedly an example of a bad compressed file.
This “test” file was placed in the .gitignore seen in the repo so the file’s abscense on github was explained. Being included as a binary test file only in the tarballs means that the malicious code isn’t on github in any form. Its nowhere to be seen until you get the tarball.
The build process then creates some highly obfuscated bash scripts on the fly during compilation that check for the existence of the files (since they won’t be there if you’re building from github). If they’re there, the scripts reassemble the object module, basically replacing the code that you would see in the repo.
Thats a simplified version of why there’s no code to see, and that’s just one aspect of this thing. It’s sneaky.


{kind=link}
I have heard multiple times from different sources that building from git source instead of using tarballs invalidates this exploit, but I do not understand how. Is anyone able to explain that?
If malicious code is in the source, and therefore in the tarball, what’s the difference?
Because m4/build-to-host.m4, the entry point, is not in the git repo, but was included by the malicious maintainer into the tarballs.
Tarballs are not built from source?
The tarballs are the official distributions of the source code. The maintainer had git remove the malicious entry point when pushing the newest versions of the source code while retaining it inside these distributions.
All of this would be avoided if Debian downloaded from GitHub’s distributions of the source code, albeit unsigned.
In that case they would have just put it in the repo, and I’m not convinced anyone would have caught it. They may have obfuscated it slightly more.
It’s totally reasonable to trust a tarball signed by the maintainer, but there probably needs to be more scrutiny when a package changes hands like this one did.
Downloading from github is how NixOS avoided getting hit. On unstable, that is, on stable a tarball gets downloaded (EDIT: fixed links).
Another reason it didn’t get hit is that the exploit is debian/redhat-specific, checking for files and env variables that just aren’t present when nix builds it. That doesn’t mean that nix couldn’t be targeted, though. Also it’s a bit iffy that replacing the package on unstable took in the order of 10 days which is 99.99% build time because it’s a full rebuild. Much better on stable but it’s not like unstable doesn’t get regular use by people, especially as you can mix+match when running NixOS.
It’s probably a good idea to make a habit of pulling directly from github (generally, VCS). Nix checks hashes all the time so upstream doing a sneak change would break the build, it’s more about the version you’re using being the one that has its version history published. Also: Why not?
Overall, who knows what else is hidden in that code, though. I’ve heard that Debian wants to roll back a whole two years and that’s probably a good idea and in general we should be much more careful about the TCB. Actually have a proper TCB in the first place, which means making it small and simple. Compilers are always going to be an issue as small is not an option there but the likes of http clients, decompressors and the like? Why can they make coffee?
I don’t understand the actual mechanics of it, but my understanding is that it’s essentially like what happened with Volkswagon and their diesel emissions testing scheme where it had a way to know it was being emissions tested and so it adapted to that.
The malicious actor had a mechanism that exempted the malicious code when built from source, presumably because it would be more likely to be noticed when building/examining the source.
Edit: a bit of grammar. Also, this is my best understanding based on what I’ve read and videos I’ve watched, but a lot of it is over my head.
Not sure why you got downvoted. This is a good analogy. It does a lot of checks to try to disable itself in testing environments. For example, setting TERM will turn it off.
The malicious code is not on the source itself, it’s on tests and other files. The building process hijacks the code and inserts the malicious content, while the code itself is clean, So the co-manteiner was able to keep it hidden in plain sight.
The malicious code wasn’t in the source code people typically read (the GitHub repo) but was in the code people typically build for official releases (the tarball). It was also hidden in files that are supposed to be used for testing, which get run as part of the official building process.
The malicious code was written and debugged at their convenience and saved as an object module linker file that had been stripped of debugger symbols (this is one of its features that made Fruend suspicious enough to keep digging when he profiled his backdoored ssh looking for that 500ms delay: there were no symbols to attribute the cpu cycles to).
It was then further obfuscated by being chopped up and placed into a pure binary file that was ostensibly included in the tarballs for the xz library build process to use as a test case file during its build process. The file was supposedly an example of a bad compressed file.
This “test” file was placed in the .gitignore seen in the repo so the file’s abscense on github was explained. Being included as a binary test file only in the tarballs means that the malicious code isn’t on github in any form. Its nowhere to be seen until you get the tarball.
The build process then creates some highly obfuscated bash scripts on the fly during compilation that check for the existence of the files (since they won’t be there if you’re building from github). If they’re there, the scripts reassemble the object module, basically replacing the code that you would see in the repo.
Thats a simplified version of why there’s no code to see, and that’s just one aspect of this thing. It’s sneaky.
I think it is the other way around. If you build from Tarball then you getting pwned