
3·
25 days agoBig ask.
Personally , I’d be overjoyed to just have embeddings available on the site.
Big ask.
Personally , I’d be overjoyed to just have embeddings available on the site.
It is good that you ask :)!
Read this: https://arxiv.org/abs/2406.02965
The tldr:
Negatives should be ‘things that appear in the image’ .
If you prompt a picture of a cat , then ‘cat’ or ‘pet’ can be useful items to place in the negative prompt.
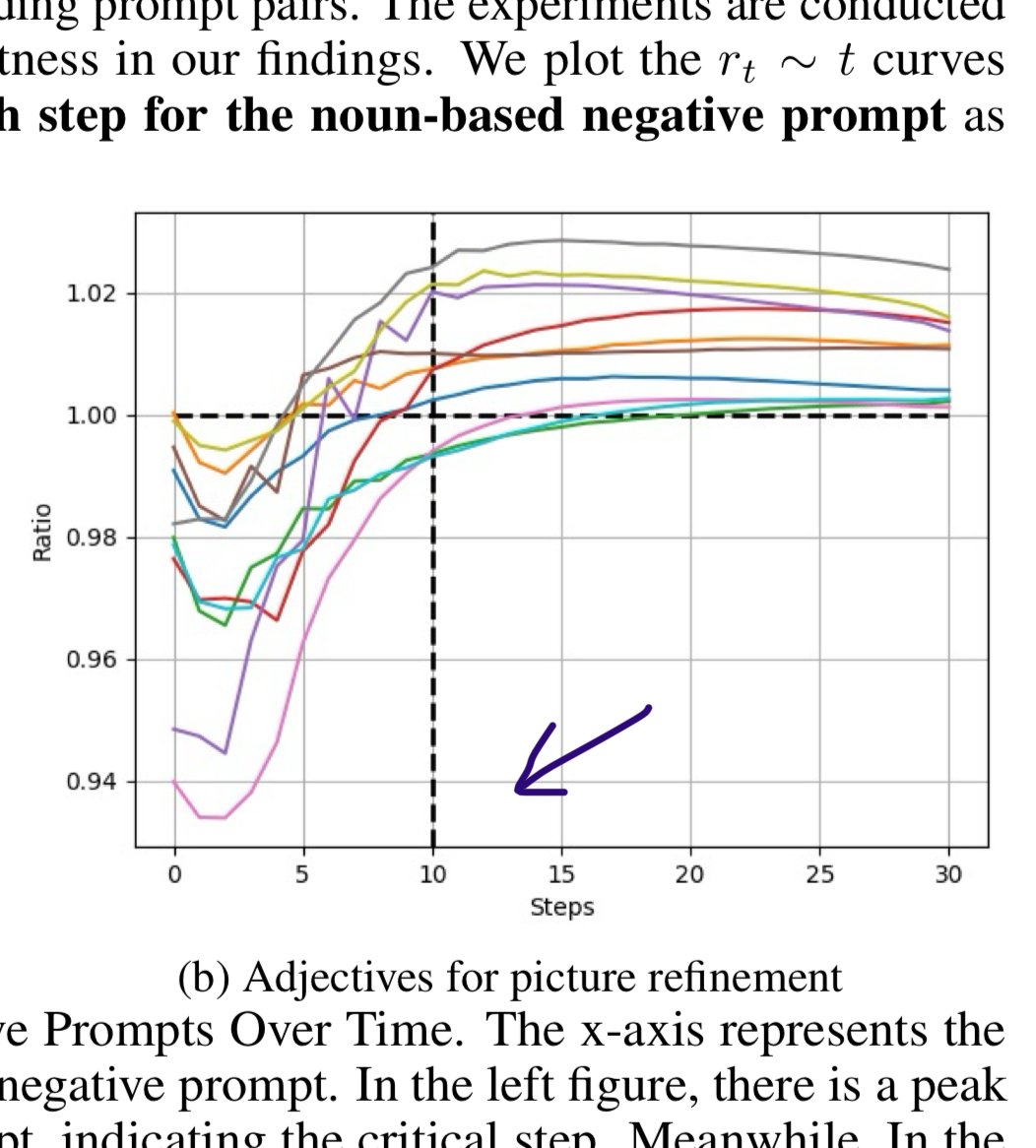
Best elimination with adjective words is with 16.7% delay , by writing \[ : neg1 neg2 neg3 :0.167 \] instead of neg1 neg2 neg3
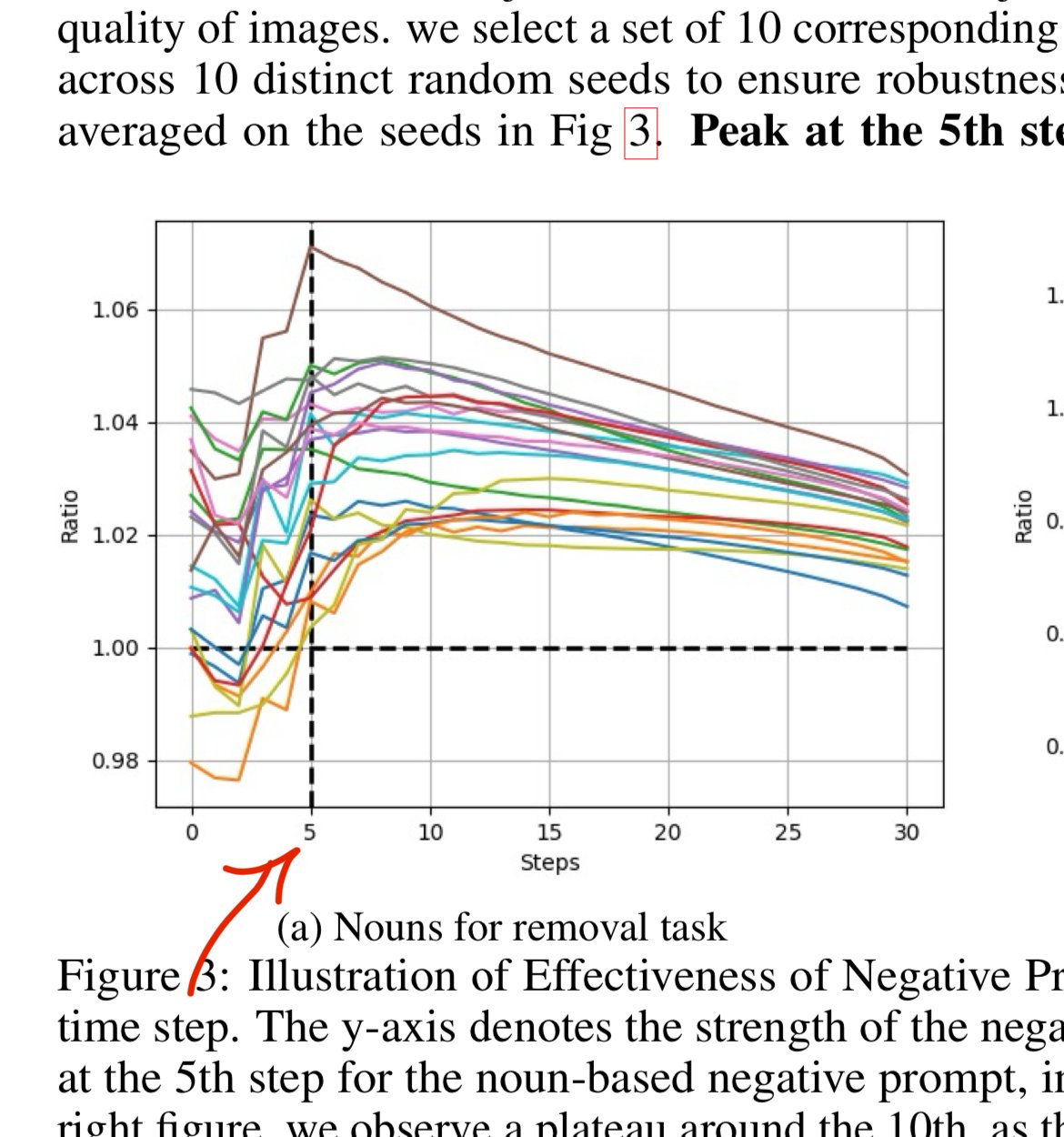
Best elimination for noun words is with 30% delay , by writing “\[ : neg1 neg2 neg3 :0.3 \]” in the negative prompt instead of "neg1 neg2 neg3 "
I appreciate you took the time to write a sincere question.
Kinda rude for people to downvote you.

Simple and cool.
Florence 2 image captioning sounds interesting to use.
Do people know of any other image-to-text models (apart from CLIP) ?
Wow , yeah I found a demo here: https://huggingface.co/spaces/Qwen/Qwen2.5
A whole host of LLM models seems to be released. Thanks for the tip!
I’ll see if I can turn them into something useful 👍
That’s good to know. I’ll try them out. Thanks.
Hmm. I mean the FLUX model looks good
, so there must maybe be some magic with the T5 ?
I have no clue, so any insights are welcome.
T5 Huggingface: https://huggingface.co/docs/transformers/model_doc/t5
T5 paper : https://arxiv.org/pdf/1910.10683
Any suggestions on what LLM i ought to use instead of T5?
Do you know where I can find documemtation on the perchance API?
Specifically createPerchanceTree ?
I need to know which functions there are , and what inputs/outputs they take.
New stuff


Paper: https://arxiv.org/abs/2303.03032
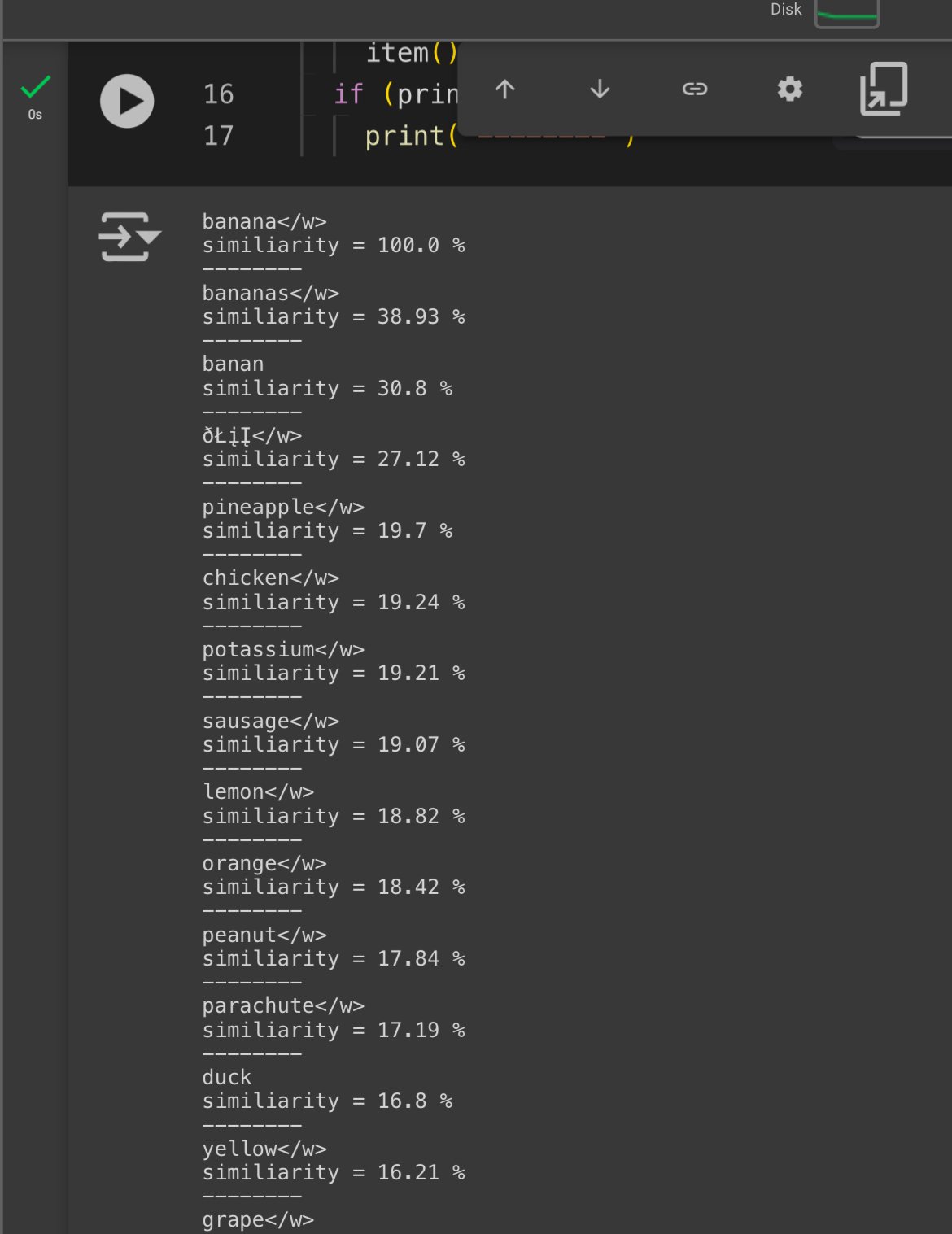
Takes only a few seconds to calculate.
Most similiar suffix tokens : "vfx "
most similiar prefix tokens : “imperi-”
From what I know it is possible to bypass the keyword trigger by writing something like _anime or _1girl
I’d say yes
Add a little code snippet that explicitly selects the model.
If a new update is coming “quite soon”
, then that could be several months from now.
And if the new update means
by default replacing the current (three?) SD 1.5 models
with a single SD 1.5 model.
Why not use all of them? As in older models + the new one , via this system?
//—//
So what I mean by this is;
In the next update ,
The new SD 1.5 model could be available by default
, and if user writes (model:::anime) , (model:::photo) or (model:::anthro)
, then it uses the “older” SD 1.5 models.
Yeah , I understand the situation.
I appreciate you telling me model selection is within the top categories on civitai.
I didn’t know multiple models were being used.
Any chance you could allow a user to specify which model to generate with , to override switching models based on keywords?
Like for example writing (model:::Anime) in the prompt to use an anime model?
Added an EDIT , to give context to “results don’t match”.
//–//
Yeah , that sounds reasonable. Thanks for pinging the dev.
But however I look at it , the Perchance model can’t be the Deliberate V2 model.
I just want the .safetensors file of the perchance SD1.5 model to be available online.
I’m not even going to adress your post.
I’ve heard this lingo before.
Godamn redditors trying to infiltrate the perchance forums.
There’s no reasoning with this rhetoric
That’s fair
But the chatrooms still have to be visible to everyone though?
If not I feel that could open up all sorts of avenues for illegal activity
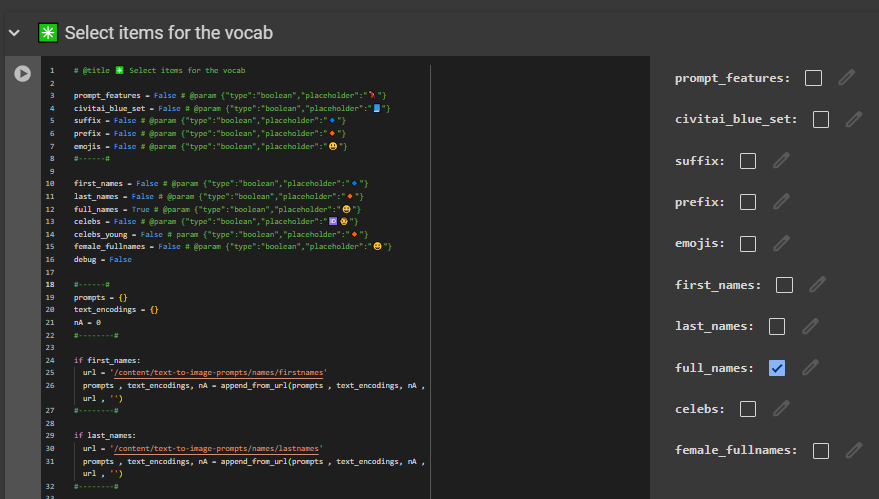
I’ve implemented that kind of system in my generator: https://perchance.org/fusion-ai-image-generator
I invoke it by letting the user write , for example ,
“photo of a #adjective# #name#”
and then prior before sending the prompt to the generator I run
“photo of a #adjective# #name#”.replaceText(“#adjective#”, adjectives.selectOne).replaceText(“#names#”, name.selectOne)
to get the randomized string
//----//
In Stable Diffusion the “prompt” is not an “instruction” as in ai-chat.
The Stable Diffusion model never refers to the prompt when generating the image.
Instead, it converts the string to numbers and runs them through layers and layers of matrices.
Like a ball tumbling down aling the pins in a pachinko machine.
SD Prompting is very “psuedo-science” since nobody really knows what this kind of grid can and can’t do with the “ball” you throw into it.
Since I’m building a randomizer around this , I’ve covered a lot of topics on this in the fusion discord: https://discord.gg/dbkbhf8H2E
//—//
Also;
NSFW topics are better asked at https://lemmy.world/c/casual_perchance.
Questions asked at this forum are better if written in a SFW context.
I see. Thanks! I can use this.
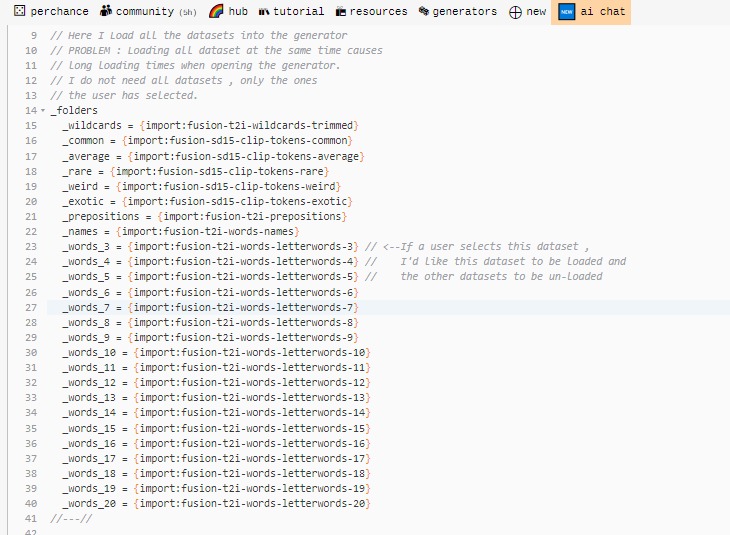
Since its async , I think what I’ll do is use the code to make a wrapper function for the dynamic import plugin, something like :
myDynamicImportWrapper( “blahblah” , default = “template-fusion-generator-dataset” )
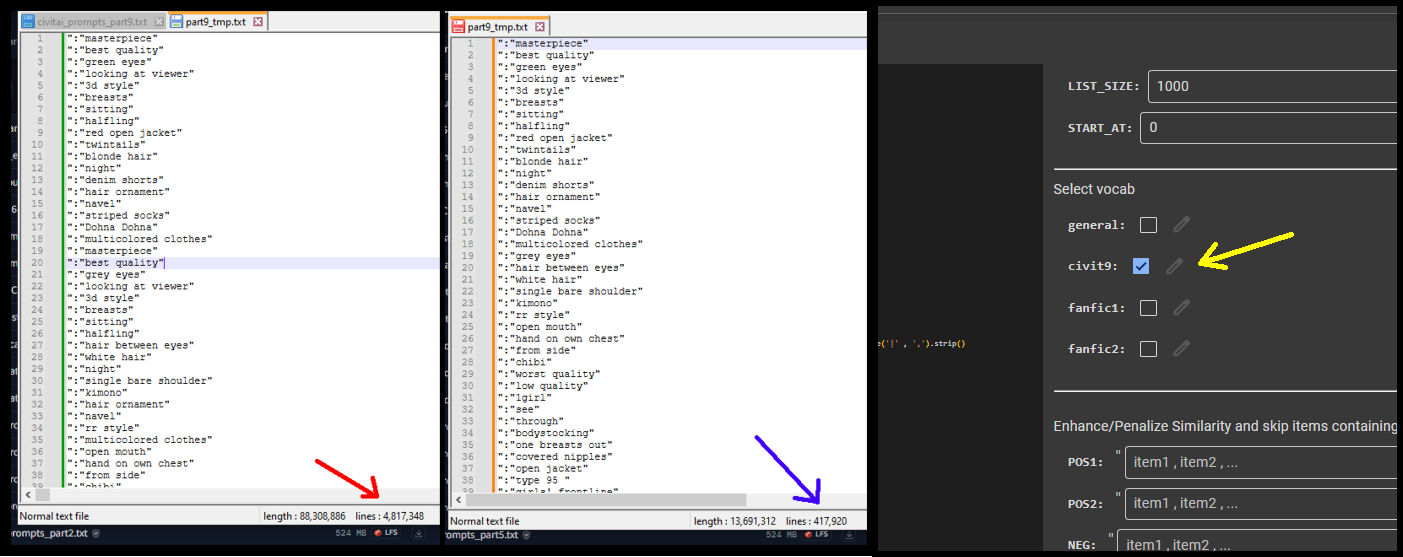{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
My solution has been to left click , select “inspect element” to open the browsers HTML window.
Then zoom out the generator as far as it goes , and scroll down so the entire image gallery (or a part of it at least) is rendered within the browser.
The ctrl+c copy the HTML and paste it in notepad++ , and use regular expressions to sort out the image prompts (and image source links) from the HTML code
Not exactly a good fix , but it gets the job done at least.